
Multiple Lineare Regressionsrechnung
Es wird die Regressionsfunktion y=f(x1,x2,...,xm) nach der Methode der kleinsten Quadrate geschätzt.
Die Regressionsrechnung wird hier für den Anwendungsfall der Prognose eingesetzt und beschrieben. Die Dateneingabe ist aber so allgemein gehalten, daß Sie auch auf Datensätze angewendet werden kann, die keine Zeitreihen sind.
Symbole:
| t | Zeitindex bzw. Index der Beobachtung |
| y(t) | abhängige Variable (in Periode) t |
| x(t,j) | unabhängige Variable j (in Periode) t |
Die Dateneingabe orientiert sich an der Matrixschreibweise aus Tempelmeier (2018), Abschnitt B.3.2.
Falls eine Regressinonsfunktion mit einem Achsenabschnitt geschätzt werden soll, dann muß eine Variable mit Einsen definiert werden. Wird diese weggelassen, dann handelt es sich um eine Regression durch den Ursprung.
Im folgenden Bild ist die Funktion y(t)=a+b*t zu schätzen. Die erste unabhängige Variable x(t,1) steht für den Achsenabschnitt, die zweite unabhängige Variable x(t,2) ist die Zeit.
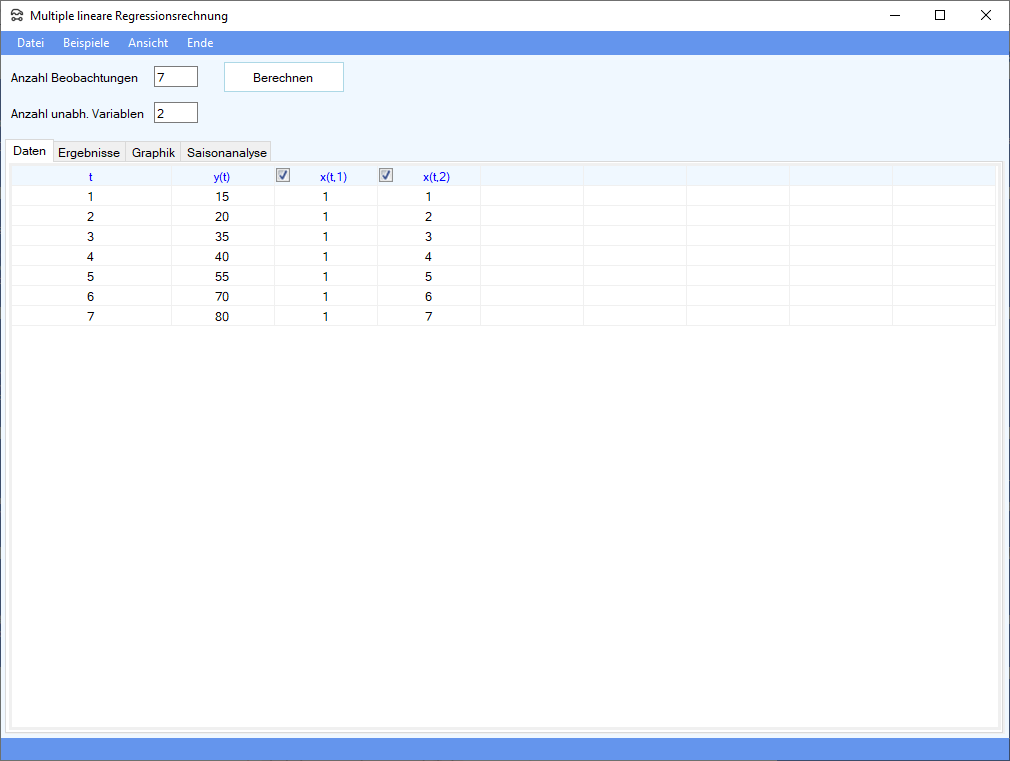
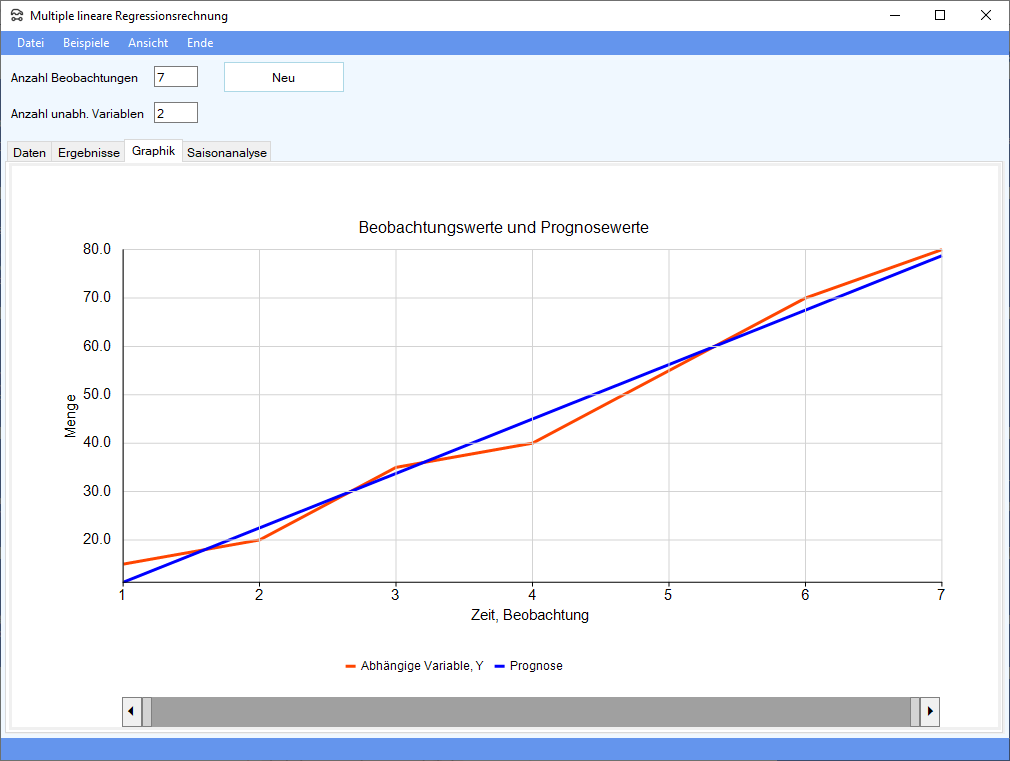
Nach Durchführung der Berechnungen erhält man folgendes Bild:
Die Ergebnisse sehen wie folgt aus:
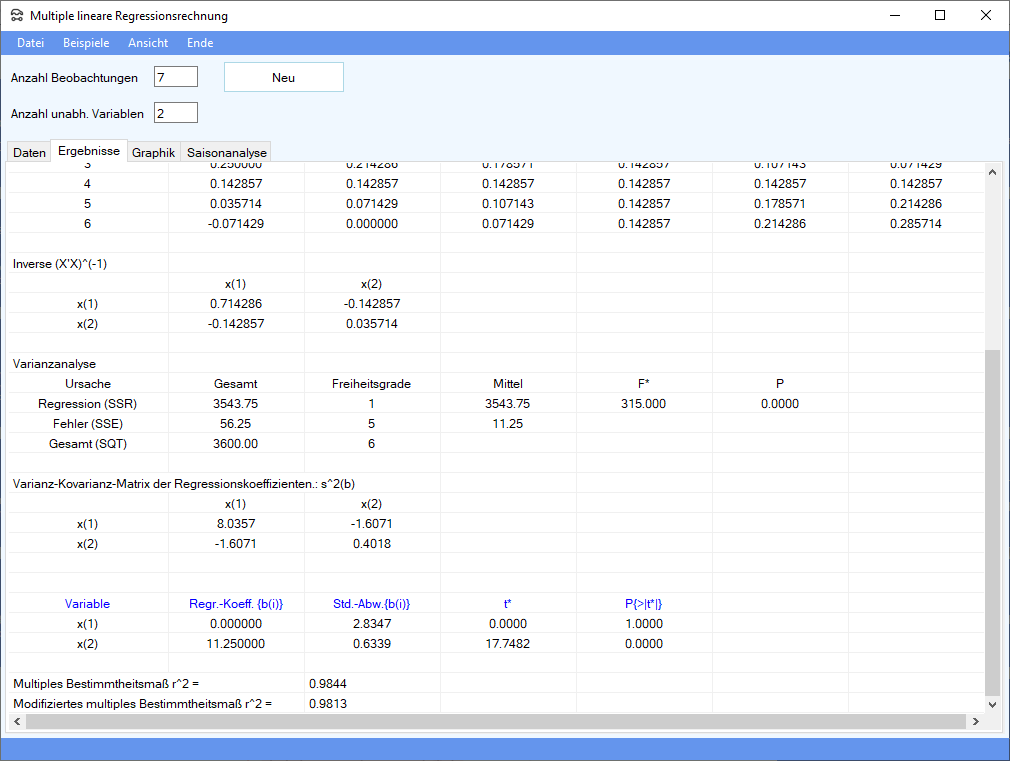
Interpretation der Ergebnisse:
| t* | t* ist die Teststatistik b(i)/Std.-Abw.{b(i)}, mit der getestet wird, ob der geschätzte Wert b(i) signifikant von 0 verschieden ist. Falls t* größer als der kritische Wert der Student-t-Verteilung ist, dann wird die Hypothese, daß der unbekannte Regressionsparameter ß(i) gleich 0 ist, abgelehnt. |
Weitere Erläuterungen der Ergebnisse findet man z.B. bei Tempelmeier (2018).
Die Daten können auf zwei Arten definiert sein:
1)
Die Daten können aus einer Datei mit der Namenserweiterung *.MLR eingelesen werden. In der ersten Zeile sind die Anzahl der Perioden (Zeilen) und die Anzahl der unabhängigen Variablen anzugeben. Für jede Periode sind dann die abhängige Variable und die unabhängigen Variablen anzugeben. Im obigen Beispiel sieht das so aus:
24 2
46;2
15;1;1
20;1;2
usw.
Als Trennzeichen kann das Semikolon oder der Tabulator verwendet werden. Dies in den Optionen festzulegen.
2)
Eine Datei mit der Namenserweiterung ".txt", die für jede Beobachtung eine Zeile "Y X1 X2 X3 ... " enthält . Die Wert sind durch Leerzeichen getrennt:
16.0 1.0 4.0
5.0 1.0 1.0
10.0 1.0 2.0
15.0 1.0 3.0
13.0 1.0 3.0
22.0 1.0 4.0
usw.
- Schira, J., Statistische Methoden der VWL und BWL - Theorie und Praxis, 5. Auflage, München (Pearson) 2016
- Tempelmeier (2018)
oder jedes Statistik-Lehrbuch, das einen Abschnitt zur Multiplen Linearen Regression enthält, z.B.
Datenschutz | © 2021 POM Prof. Tempelmeier GmbH | Imprint